2种部署方式简介
第一种
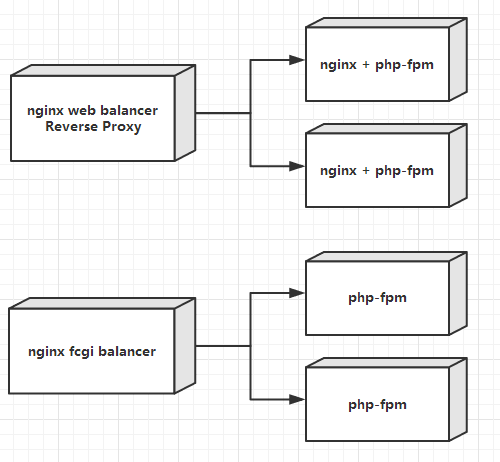
- 前置1台nginx服务器做HTTP反向代理和负载均衡
- 后面多态服务器部署Nginx Web服务和php-fpm提供的fast cgi服务
第二种
- 前置1台nginx服务器做Web服务
- 后面服务器只部署php-fpm服务,供nginx服务器调用
- 前置1台nginx服务器,在调用后面多例php-fpm服务时,也可以做到负载均衡
如下图 :
对比
从系统设计角度
第一种部署是常见部署方式,大中小规模网站都能适用。
第二种,web服务和php-fpm服务部署在不同服务器上,更加细致。但有几个问题:
- 前置nginx充当Web服务。对静态资源的访问、压缩传输、缓存设置等,也都集中在这台服务器上。一旦访问量变多,压力变大,容易成为瓶颈。
- 如果静态资源都存放于CDN,不需要HTTP 压缩传输,这种部署方式还算比较合理;
- 承接上面两点,还可以对这种部署方式进行优化。如前置nginx负载均衡和反向代理,中间是nginx Web服务,后面部署php-fpm服务。
从性能角度
相比第二种部署方式,第一种多走了一次进程间交互。
- 按照第一种部署,当一个http请求过来,先是nginx反向代理转发至nginx Web服务(通过网络),Web服务再通过fastcgi协议与php-fpm进行交互(进程间交互);
- 按照第二种部署,当一个http请求过来,充当Web服务的nginx,直接通过网络与php-fpm进行交互
第一种部署,通过网络交互的是HTTP协议,第二种通过网络交互的是fast-cgi协议, 这两种协议对比如何呢?
- fast cgi 的数据包会比HTTP稍微大一些,fast cgi协议会比HTTP携带更多的参数信息、传输控制信息等等。
- fast cgi 协议比HTTP协议格式化严格一些,解析起来速度更快一些。
从运维角度
-
第一种是最常见的部署方式,后面所有服务器上的服务都是同构的,简单粗放。
-
第二种则是将nginx和php-fpm单独分开部署,不同服务在服务器集群上的分布更加细致。通过统计Web服务中的压力分布,可以更加精细地利用硬件资源。运维成本也更高。
从开发测试角度
两种部署方式都不合适开发环境或测试环境,都仅适用于生产环境。
开发和测试环境把nginx和PHP部署到一台服务器上即可,也不需要反向代理和负载均衡。
总结
如果是LAMP环境的部署,第一种比较常见。
如果不是LAMP,是nginx和其他fastcgi服务交互,比如C/C++、java的fastcgi程序,在大规模的网络应用中,类似第二种的部署是常见的。做到不同服务之间分开部署,反而是简化了系统的网络结构,更加便于维护。
后记
此篇博文的内容,都来自于和百度前同事在QQ群里的讨论。